
[ad_1]
Selecting the mannequin that works finest to your information
22 hours in the past

OpenAI just lately launched their new technology of embedding fashions, referred to as embedding v3, which they describe as their most performant embedding fashions, with greater multilingual performances. The fashions are available two courses: a smaller one referred to as text-embedding-3-small, and a bigger and extra highly effective one referred to as text-embedding-3-large.
Little or no info was disclosed regarding the way in which these fashions had been designed and educated. As their earlier embedding mannequin launch (December 2022 with the ada-002 mannequin class), OpenAI once more chooses a closed-source method the place the fashions could solely be accessed via a paid API.
However are the performances so good that they make it price paying?
The motivation for this put up is to empirically evaluate the performances of those new fashions with their open-source counterparts. We’ll depend on an information retrieval workflow, the place probably the most related paperwork in a corpus should be discovered given a consumer question.
Our corpus would be the European AI Act, which is presently in its last phases of validation. An attention-grabbing attribute of this corpus, in addition to being the first-ever authorized framework on AI worldwide, is its availability in 24 languages. This makes it potential to check the accuracy of knowledge retrieval throughout totally different households of languages.
The put up will undergo the 2 predominant following steps:
- Generate a customized artificial query/reply dataset from a multilingual textual content corpus
- Evaluate the accuracy of OpenAI and state-of-the-art open-source embedding fashions on this practice dataset.
The code and information to breed the outcomes introduced on this put up are made out there in this Github repository. Notice that the EU AI Act is used for instance, and the methodology adopted on this put up could be tailored to different information corpus.
Allow us to first begin by producing a dataset of questions and solutions (Q/A) on customized information, which will probably be used to evaluate the efficiency of various embedding fashions. The advantages of producing a customized Q/A dataset are twofold. First, it avoids biases by guaranteeing that the dataset has not been a part of the coaching of an embedding mannequin, which can occur on reference benchmarks resembling MTEB. Second, it permits to tailor the evaluation to a selected corpus of knowledge, which could be related within the case of retrieval augmented functions (RAG) for instance.
We are going to observe the straightforward course of steered by Llama Index of their documentation. The corpus is first break up right into a set of chunks. Then, for every chunk, a set of artificial questions are generated by means of a giant language mannequin (LLM), such that the reply lies within the corresponding chunk. The method is illustrated beneath:

Implementing this technique is easy with an information framework for LLM resembling Llama Index. The loading of the corpus and splitting of textual content could be conveniently carried out utilizing high-level features, as illustrated with the next code.
from llama_index.readers.internet import SimpleWebPageReader
from llama_index.core.node_parser import SentenceSplitterlanguage = "EN"
url_doc = "https://eur-lex.europa.eu/legal-content/"+language+"/TXT/HTML/?uri=CELEX:52021PC0206"
paperwork = SimpleWebPageReader(html_to_text=True).load_data([url_doc])
parser = SentenceSplitter(chunk_size=1000)
nodes = parser.get_nodes_from_documents(paperwork, show_progress=True)
On this instance, the corpus is the EU AI Act in English, taken immediately from the Internet utilizing this official URL. We use the draft model from April 2021, as the ultimate model just isn’t but out there for all European languages. On this model, English language could be changed within the URL by any of the 23 different EU official languages to retrieve the textual content in a special language (BG for Bulgarian, ES for Spanish, CS for Czech, and so forth).

We use the SentenceSplitter object to separate the doc in chunks of 1000 tokens. For English, this leads to about 100 chunks.
Every chunk is then offered as context to the next immediate (the default immediate steered within the Llama Index library):
prompts={}
prompts["EN"] = """
Context info is beneath.---------------------
{context_str}
---------------------
Given the context info and never prior data, generate solely questions based mostly on the beneath question.
You're a Trainer/ Professor. Your process is to setup {num_questions_per_chunk} questions for an upcoming quiz/examination.
The questions needs to be various in nature throughout the doc. Limit the inquiries to the context info offered."
"""
The immediate goals at producing questions in regards to the doc chunk, as if a instructor had been getting ready an upcoming quiz. The variety of inquiries to generate for every chunk is handed because the parameter ‘num_questions_per_chunk’, which we set to 2. Questions can then be generated by calling the generate_qa_embedding_pairs from the Llama Index library:
from llama_index.llms import OpenAI
from llama_index.legacy.finetuning import generate_qa_embedding_pairsqa_dataset = generate_qa_embedding_pairs(
llm=OpenAI(mannequin="gpt-3.5-turbo-0125",additional_kwargs={'seed':42}),
nodes=nodes,
qa_generate_prompt_tmpl = prompts[language],
num_questions_per_chunk=2
)
We rely for this process on the GPT-3.5-turbo-0125 mode from OpenAI, which is in keeping with OpenAI the flagship mannequin of this household, supporting a 16K context window and optimized for dialog (https://platform.openai.com/docs/fashions/gpt-3-5-turbo).
The ensuing objet ‘qa_dataset’ accommodates the questions and solutions (chunks) pairs. For example of generated questions, right here is the consequence for the primary two questions (for which the ‘reply’ is the primary chunk of textual content):
1) What are the principle targets of the proposal for a Regulation laying down harmonised guidelines on synthetic intelligence (Synthetic Intelligence Act) in keeping with the explanatory memorandum?
2) How does the proposal for a Regulation on synthetic intelligence goal to deal with the dangers related to the usage of AI whereas selling the uptake of AI within the European Union, as outlined within the context info?
The variety of chunks and questions will depend on the language, starting from round 100 chunks and 200 questions for English, to 200 chunks and 400 questions for Hungarian.
Our analysis operate follows the Llama Index documentation and consists in two predominant steps. First, the embeddings for all solutions (doc chunks) are saved in a VectorStoreIndex for environment friendly retrieval. Then, the analysis operate loops over all queries, retrieves the highest okay most related paperwork, and the accuracy of the retrieval in assessed by way of MRR (Imply Reciprocal Rank).
def consider(dataset, embed_model, insert_batch_size=1000, top_k=5):
# Get corpus, queries, and related paperwork from the qa_dataset object
corpus = dataset.corpus
queries = dataset.queries
relevant_docs = dataset.relevant_docs# Create TextNode objects for every doc within the corpus and create a VectorStoreIndex to effectively retailer and retrieve embeddings
nodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]
index = VectorStoreIndex(
nodes, embed_model=embed_model, insert_batch_size=insert_batch_size
)
retriever = index.as_retriever(similarity_top_k=top_k)
# Put together to gather analysis outcomes
eval_results = []
# Iterate over every question within the dataset to guage retrieval efficiency
for query_id, question in tqdm(queries.objects()):
# Retrieve the top_k most related paperwork for the present question and extract the IDs of the retrieved paperwork
retrieved_nodes = retriever.retrieve(question)
retrieved_ids = [node.node.node_id for node in retrieved_nodes]
# Test if the anticipated doc was among the many retrieved paperwork
expected_id = relevant_docs[query_id][0]
is_hit = expected_id in retrieved_ids # assume 1 related doc per question
# Calculate the Imply Reciprocal Rank (MRR) and append to outcomes
if is_hit:
rank = retrieved_ids.index(expected_id) + 1
mrr = 1 / rank
else:
mrr = 0
eval_results.append(mrr)
# Return the typical MRR throughout all queries as the ultimate analysis metric
return np.common(eval_results)
The embedding mannequin is handed to the analysis operate by the use of the `embed_model` argument, which for OpenAI fashions is an OpenAIEmbedding object initialised with the identify of the mannequin, and the mannequin dimension.
from llama_index.embeddings.openai import OpenAIEmbeddingembed_model = OpenAIEmbedding(mannequin=model_spec['model_name'],
dimensions=model_spec['dimensions'])
The dimensions API parameter can shorten embeddings (i.e. take away some numbers from the top of the sequence) with out the embedding shedding its concept-representing properties. OpenAI for instance suggests of their annoucement that on the MTEB benchmark, an embedding could be shortened to a dimension of 256 whereas nonetheless outperforming an unshortened text-embedding-ada-002 embedding with a dimension of 1536.
We ran the analysis operate on 4 totally different OpenAI embedding fashions:
- two variations of
text-embedding-3-large: one with the bottom potential dimension (256), and the opposite one with the best potential dimension (3072). These are referred to as ‘OAI-large-256’ and ‘OAI-large-3072’. - OAI-small: The
text-embedding-3-smallembedding mannequin, with a dimension of 1536. - OAI-ada-002: The legacy
text-embedding-ada-002mannequin, with a dimension of 1536.
Every mannequin was evaluated on 4 totally different languages: English (EN), French (FR), Czech (CS) and Hungarian (HU), masking examples of Germanic, Romance, Slavic and Uralic language, respectively.
embeddings_model_spec = {
}embeddings_model_spec['OAI-Large-256']={'model_name':'text-embedding-3-large','dimensions':256}
embeddings_model_spec['OAI-Large-3072']={'model_name':'text-embedding-3-large','dimensions':3072}
embeddings_model_spec['OAI-Small']={'model_name':'text-embedding-3-small','dimensions':1536}
embeddings_model_spec['OAI-ada-002']={'model_name':'text-embedding-ada-002','dimensions':None}
outcomes = []
languages = ["EN", "FR", "CS", "HU"]
# Loop via all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
# Loop via all fashions
for model_name, model_spec in embeddings_model_spec.objects():
# Get mannequin
embed_model = OpenAIEmbedding(mannequin=model_spec['model_name'],
dimensions=model_spec['dimensions'])
# Assess embedding rating (by way of MRR)
rating = consider(qa_dataset, embed_model)
outcomes.append([language, model_name, score])
df_results = pd.DataFrame(outcomes, columns = ["Language" ,"Embedding model", "MRR"])
The ensuing accuracy by way of MRR is reported beneath:

As anticipated, for the massive mannequin, higher performances are noticed with the bigger embedding dimension of 3072. In contrast with the small and legacy Ada fashions, the massive mannequin is nevertheless smaller than we’d have anticipated. For comparability, we additionally report beneath the performances obtained by the OpenAI fashions on the MTEB benchmark.

It’s attention-grabbing to notice that the variations in performances between the massive, small and Ada fashions are a lot much less pronounced in our evaluation than within the MTEB benchmark, reflecting the truth that the typical performances noticed in massive benchmarks don’t essentially mirror these obtained on customized datasets.
The open-source analysis round embeddings is kind of energetic, and new fashions are often printed. A very good place to maintain up to date in regards to the newest printed fashions is the Hugging Face 😊 MTEB leaderboard.
For the comparability on this article, we chosen a set of 4 embedding fashions just lately printed (2024). The factors for choice had been their common rating on the MTEB leaderboard and their potential to take care of multilingual information. A abstract of the principle traits of the chosen fashions are reported beneath.
- E5-Mistral-7B-instruct (E5-mistral-7b): This E5 embedding mannequin by Microsoft is initialized from Mistral-7B-v0.1 and fine-tuned on a mix of multilingual datasets. The mannequin performs finest on the MTEB leaderboard, however can also be by far the largest one (14GB).
- multilingual-e5-large-instruct (ML-E5-large): One other E5 mannequin from Microsoft, meant to higher deal with multilingual information. It’s initialized from xlm-roberta-large and educated on a mix of multilingual datasets. It’s a lot smaller (10 occasions) than E5-Mistral, but in addition has a a lot decrease context dimension (514).
- BGE-M3: The mannequin was designed by the Beijing Academy of Synthetic Intelligence, and is their state-of-the-art embedding mannequin for multilingual information, supporting greater than 100 working languages. It was not but benchmarked on the MTEB leaderboard as of twenty-two/02/2024.
- nomic-embed-text-v1 (Nomic-Embed): The mannequin was designed by Nomic, and claims higher performances than OpenAI Ada-002 and text-embedding-3-small whereas being solely 0.55GB in dimension. Curiously, the mannequin is the primary to be totally reproducible and auditable (open information and open-source coaching code).
The code for evaluating these open-source fashions is much like the code used for OpenAI fashions. The primary change lies within the mannequin specs, the place extra particulars resembling most context size and pooling sorts should be specified. We then consider every mannequin for every of the 4 languages:
embeddings_model_spec = {
}embeddings_model_spec['E5-mistral-7b']={'model_name':'intfloat/e5-mistral-7b-instruct','max_length':32768, 'pooling_type':'last_token',
'normalize': True, 'batch_size':1, 'kwargs': {'load_in_4bit':True, 'bnb_4bit_compute_dtype':torch.float16}}
embeddings_model_spec['ML-E5-large']={'model_name':'intfloat/multilingual-e5-large','max_length':512, 'pooling_type':'imply',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['BGE-M3']={'model_name':'BAAI/bge-m3','max_length':8192, 'pooling_type':'cls',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}}
embeddings_model_spec['Nomic-Embed']={'model_name':'nomic-ai/nomic-embed-text-v1','max_length':8192, 'pooling_type':'imply',
'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'trust_remote_code' : True}}
outcomes = []
languages = ["EN", "FR", "CS", "HU"]
# Loop via all fashions
for model_name, model_spec in embeddings_model_spec.objects():
print("Processing mannequin : "+str(model_spec))
# Get mannequin
tokenizer = AutoTokenizer.from_pretrained(model_spec['model_name'])
embed_model = AutoModel.from_pretrained(model_spec['model_name'], **model_spec['kwargs'])
if model_name=="Nomic-Embed":
embed_model.to('cuda')
# Loop via all languages
for language in languages:
# Load dataset
file_name=language+"_dataset.json"
qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name)
start_time_assessment=time.time()
# Assess embedding rating (by way of hit price at okay=5)
rating = consider(qa_dataset, tokenizer, embed_model, model_spec['normalize'], model_spec['max_length'], model_spec['pooling_type'])
# Get length of rating evaluation
duration_assessment = time.time()-start_time_assessment
outcomes.append([language, model_name, score, duration_assessment])
df_results = pd.DataFrame(outcomes, columns = ["Language" ,"Embedding model", "MRR", "Duration"])
The ensuing accuracies by way of MRR are reported beneath.

BGE-M3 seems to supply the most effective performances, adopted on common by ML-E5-Massive, E5-mistral-7b and Nomic-Embed. BGE-M3 mannequin just isn’t but benchmarked on the MTEB leaderboard, and our outcomes point out that it might rank greater than different fashions. It’s also attention-grabbing to notice that whereas BGE-M3 is optimized for multilingual information, it additionally performs higher for English than the opposite fashions.
We moreover report the processing occasions for every embedding mannequin beneath.

The E5-mistral-7b, which is greater than 10 occasions bigger than the opposite fashions, is with out shock by far the slowest mannequin.
Allow us to put side-by-side of the efficiency of the eight examined fashions in a single determine.
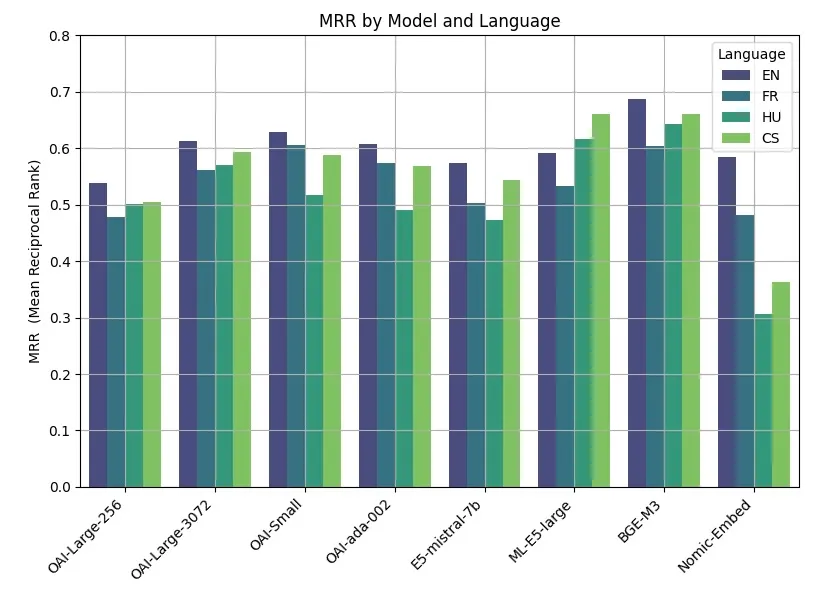
The important thing observations from these outcomes are:
- Finest performances had been obtained by open-source fashions. The BGE-M3 mannequin, developed by the Beijing Academy of Synthetic Intelligence, emerged as the highest performer. The mannequin has the identical context size as OpenAI fashions (8K), for a dimension of two.2GB.
- Consistency Throughout OpenAI’s Vary. The performances of the massive (3072), small and legacy OpenAI fashions had been very related. Decreasing the embedding dimension of the massive mannequin (256) nevertheless led to a degradation of performances.
- Language Sensitivity. Virtually all fashions (besides ML-E5-large) carried out finest on English. Vital variations in performances had been noticed in languages like Czech and Hungarian.
Must you due to this fact go for a paid OpenAI subscription, or for internet hosting an open-source embedding mannequin?
OpenAI’s current worth revision has made entry to their API considerably extra inexpensive, with the price now standing at $0.13 per million tokens. Coping with a million queries monthly (and assuming that every question includes round 1K token) would due to this fact value on the order of $130. Relying in your use case, it might due to this fact not be cost-effective to hire and preserve your personal embedding server.
Value-effectiveness is nevertheless not the only real consideration. Different elements resembling latency, privateness, and management over information processing workflows may additionally should be thought of. Open-source fashions supply the benefit of full information management, enhancing privateness and customization. However, latency points have been noticed with OpenAI’s API, generally leading to prolonged response occasions.
In conclusion, the selection between open-source fashions and proprietary options like OpenAI’s doesn’t lend itself to an easy reply. Open-source embeddings current a compelling choice, combining efficiency with better management over information. Conversely, OpenAI’s choices should still enchantment to these prioritizing comfort, particularly if privateness considerations are secondary.
Notes:
[ad_2]