[ad_1]
Methods for Overcoming the Challenges of Scaling Open-Supply AI Fashions in Manufacturing
In case you’re studying this text, you in all probability want no introduction to some great benefits of deploying open-source fashions. Over the previous couple of years, we’ve got seen unimaginable progress within the each the amount and high quality of open supply fashions.
- Platforms corresponding to Hugging Face have democratized entry to a big selection of fashions, together with Massive Language Fashions (LLMs) and diffusion fashions, empowering builders to innovate freely and effectively.
- Builders take pleasure in larger autonomy, as they will fine-tune and mix totally different fashions at will, resulting in progressive approaches like Retrieval-Augmented Technology (RAG) and the creation of superior brokers.
- From an financial perspective, open-source fashions present substantial price financial savings, enabling using smaller, specialised fashions which might be extra budget-friendly in comparison with general-purpose fashions like GPT-4.
Open-source fashions current a lovely answer, however what’s the following hurdle? Not like utilizing a mannequin endpoint like OpenAI, the place the mannequin is a scalable black field behind the API, deploying your personal open-source fashions introduces scaling challenges. It’s essential to make sure that your mannequin scales successfully with manufacturing site visitors and maintains a seamless expertise throughout site visitors spikes. Moreover, it’s essential to handle prices effectively, so that you solely pay for what you employ and keep away from any monetary surprises on the finish of the month.
Apparently, this appears like a problem that fashionable serverless architectures, like AWS Lambda, have already solved — an answer which have existed for nearly a decade. Nevertheless, in the case of AI mannequin deployment, this isn’t fairly the case.
The constraints of serverless features for AI deployments are multifaceted.
- No GPU assist. Platforms like AWS Lambda don’t assist GPU. This isn’t merely a technical oversight; it’s rooted in architectural and sensible issues.
- GPUs can’t be simply shared. GPUs, whereas extremely parallelizable as gadgets, shouldn’t be as versatile in dealing with a number of inference duties on totally different fashions concurrently.
- GPUs are costly. They’re distinctive for mannequin inferencetasks however pricey to take care of, particularly if not utilized constantly.
Subsequent, let’s check out our scaling journey and the essential classes we’ve got discovered alongside the way in which.
Earlier than we may even start to work on scaling, we’ve got the infamous “chilly begin” drawback. This challenge presents itself in three totally different levels:

- Cloud provisioning: This section includes the time it takes for a cloud supplier to allocate an occasion and combine it into our cluster. This course of varies extensively, starting from as fast as 30 seconds to a number of minutes, and in some circumstances, even hours, particularly for high-demand situations just like the Nvidia A100 and H100 GPUs.
- Container picture pulling: Not like easy Python job photos, AI mannequin serving photos are very complicated, because of the dependencies and customized libraries they require. Though cloud suppliers boast multi-gigabit community bandwidth, our expertise usually noticed obtain speeds far under them, with picture pulling time about 3 minutes.
- Mannequin loading. The time required right here is essentially depending on the mannequin’s measurement, with bigger fashions like LLMs and diffusion fashions taking considerably longer time because of their billions of parameters. For instance, loading a 5GB mannequin like Steady Diffusion 2 would possibly take roughly 1.3 minutes with 1Gbps community bandwidth, whereas bigger fashions like Llama 13B and Mixtral 8x7B may require 3.5 minutes and 12.5 minutes respectively.
Every section of the chilly begin challenge calls for particular methods to reduce delays. Within the following sections, we’ll discover every of them in additional element, sharing our methods and options.
Cloud provisioning
In distinction to the homogeneous surroundings of serverless CPUs, managing a various vary of compute occasion varieties is essential when coping with GPUs, every tailor-made for particular use circumstances. For example, IO-bound LLMs require excessive GPU reminiscence bandwidth and capability, whereas generative fashions want extra highly effective GPU compute.
Making certain availability throughout peak site visitors by sustaining all GPU occasion varieties may result in prohibitively excessive prices. To keep away from the monetary pressure of idle situations, we applied a “standby situations” mechanism. Somewhat than getting ready for the utmost potential load, we maintained a calculated variety of standby situations that match the incremental scaling step sizes. For instance, if we scale by two GPUs at a time, we have to have two standby situations prepared. This permits us to rapidly add assets to our serving fleet as demand surges, considerably lowering wait time, whereas conserving price manageable.

In a multi-tenant surroundings, the place a number of groups or, in our case, a number of organizations, share a standard useful resource pool, we will obtain extra environment friendly utilization charges. This shared surroundings permits us to steadiness various useful resource calls for, contributing to improved price effectivity. Nevertheless, managing multi-tenancy introduces challenges, corresponding to imposing quotas and guaranteeing community isolation, which may add complexity to the cluster.
Container picture pulling
Serverless CPU workloads usually use light-weight photos, just like the Python slim picture (round 154 MB). In stark distinction, a container picture constructed for serving an LLM might be a lot bigger (6.7 GB); the majority of this measurement comes from the assorted dependencies required to run the AI mannequin.

Regardless of high-bandwidth networks marketed by cloud suppliers, the truth usually falls quick, with precise obtain speeds being a fraction of the promised charges.
Virtually, a good portion of the recordsdata had been by no means used. A method is to optimize the container picture itself, however that rapidly proved to be unmanageable. As an alternative, we shifted our focus to an on-demand file pulling method. Particularly, we first downloaded solely the picture metadata, with the precise distant recordsdata being fetched later as wanted. As well as, we leveraged peer-to-peer networking inside the cluster to dramatically enhance pulling effectivity.

With these optimizations, we lowered the picture pulling time from a number of minutes to mere seconds. Nevertheless, everyone knows this measurement is “dishonest” because the precise recordsdata usually are not pulled at this stage. The true file pulling happens when the service runs. Due to this fact, it’s essential to have a service framework that lets you outline behaviors at numerous lifecycle levels, corresponding to initialization and serving. By doing the entire bootstrapping throughout initialization, we will be sure that all file dependencies are pulled. This fashion, in the case of serving time, there aren’t any delays attributable to file pulling.

Within the above instance, mannequin loading is completed through the initialization lifecycle inside __init__ and serving occurs inside the @bentoml.api named txt2img.
Mannequin loading
Initially, probably the most easy technique for mannequin loading was to fetch it instantly from a distant retailer like Hugging Face. Utilizing Content material Supply Networks (CDNs), NVMe SSDs, and shared reminiscence, we may take away among the bottlenecks. Whereas this labored, it was removed from optimum.
To enhance this course of, we thought of utilizing in-region community bandwidth. We seeded fashions in our distributed file methods and broke them into smaller chunks, permitting for parallel downloads. This drastically improved efficiency, however we nonetheless encountered cloud supplier’s community bandwidth bottlenecks.
In response, we additional optimized to leverage in-cluster community bandwidth through the use of peer-to-peer sharing and tapping into native caches. Whereas the enhancements had been substantial, they added a layer of complexity to the method, which we have to summary away from the builders.

Even with the above practices, we nonetheless endure from a sequential bottleneck: the necessity to await every step to finish earlier than continuing with the following. Fashions needed to be downloaded to persistent drive totally earlier than loading into CPU reminiscence, after which into the GPU.

We turned to a stream-based technique for loading mannequin weights, utilizing the distributed file cache system we had in place. This method permits applications to function as if all recordsdata had been logically obtainable on disk. In actuality, the required knowledge is fetched on-demand from distant storage due to this fact bypassed disk writing. By leveraging a format like Safetensors, we will effectively load the mannequin weights into the primary reminiscence via reminiscence mapping (mmap) earlier than loading to the GPU reminiscence in a streaming trend.
Furthermore, we adopted asynchronous writing to disk. By doing so, we created a faster-access cache layer on the native disk. Thus, new deployments with solely code adjustments may bypass the slower distant storage fetch section, studying the mannequin weights from native cache instantly.
To summarize, we managed to optimize the chilly begin time and we had been pleased with the outcomes:
- No cloud provision delay with standby situations.
- Quicker container picture pulling with on-demand and peer-to-peer streaming.
- Accelerated mannequin loading time with distributed file methods, peer-to-peer caching, and streamed loading to GPU reminiscence.
- Parallelized picture pulling and mannequin loading enabled by service framework.
Subsequent, we have to establish probably the most indicative sign for scaling AI mannequin deployments on GPUs.
Useful resource utilization metrics
Initially, we thought of CPU utilization. It’s easy and has an intuitive default threshold, corresponding to 80%. Nevertheless, the plain disadvantage is that CPU metrics don’t seize GPU utilization. Moreover, the International Interpreter Lock (GIL) in Python limits parallelism, stopping excessive CPU utilization on multi-core situations, making CPU utilization a much less possible metric.
We additionally explored GPU utilization as a extra direct measure of our fashions’ workloads. Nevertheless, we encountered a difficulty: the GPU utilization reported by instruments like nvml did not precisely characterize the precise utilization of the GPU. This metric samples kernel utilization over a time frame, and a GPU is taken into account utilized if not less than one kernel is executing. This aligns with our remark that higher efficiency can usually be achieved via improved batching, though the GPU gadget was already reported as having excessive utilization.
Observe: Based on the NVIDIA documentation, utilization.gpu means “% of time over the previous pattern interval throughout which a number of kernels was executing on the GPU. The pattern interval could also be between 1 second and 1/6 second relying on the product”.
Useful resource-based metrics are inherently retrospective as they solely mirror utilization after the assets have been consumed. They’re additionally capped at 100%, which presents an issue: when scaling based mostly on these metrics, the utmost ratio for adjustment is usually the present utilization over the specified threshold (see scaling components under). This leads to a conservative scale-up habits that doesn’t essentially match the precise demand of manufacturing site visitors.
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
Request-based metrics
We turned to request-based metrics for extra proactive signaling which might be additionally not capped at a 100%.
QPS is a widely known metric for its simplicity. Nevertheless, its software in generative AI, corresponding to with LLMs, remains to be a query. QPS shouldn’t be simple to configure and because of the variable price per request, which relies on the variety of tokens processed and generated, utilizing QPS as a scaling metric can result in inaccuracies.
Concurrency, then again, has confirmed to be a perfect metric for reflecting the precise load on the system. It represents the variety of energetic requests both queued or being processed. This metric:
- Exactly displays the load on the system. Little’s Regulation, which states that QPS multiplied by common latency equals concurrency, offers a sublime method to perceive the connection between QPS and concurrency. In observe, the common latency per request is moderately unknown in mannequin serving. Nevertheless, by measuring concurrency, we don’t have to calculate common latency.
- Precisely calculate the specified replicas utilizing the scaling components. Permitting the deployment to instantly scale to the perfect measurement with out intermediate steps.
- Straightforward to configure based mostly on batch measurement. For non-batchable fashions, it’s merely the variety of GPUs, since every can solely deal with one era job at a time. For fashions that assist batching, the batch measurement determines the concurrency stage.
For concurrency to work, we want the assist from the service framework to mechanically instrument concurrency as a metric and serve it as a scaling sign for the deployment platform. We should additionally set up proper scaling insurance policies to assist towards overzealous scale-up throughout a site visitors spike or untimely scale-down when site visitors is sparse.
A one other essential mechanism we built-in with concurrency is the request queue. It acts as a buffer and an orchestrator, guaranteeing that incoming requests are dealt with effectively and with out overloading any single server reproduction.
In a state of affairs with no request queue, all incoming requests are dispatched on to the server (6 requests within the picture under). If a number of requests arrive concurrently, and there’s just one energetic server reproduction, it turns into a bottleneck. The server tries to course of every request in a first-come-first-serve method, usually resulting in timeouts and a foul shopper expertise.

Conversely, with a request queue in place, the server consumes requests at an optimum charge, processing at a charge based mostly on the concurrency outlined for the service. When extra server replicas scale up, they too start to drag from the queue. This mechanism prevents any single server from changing into overwhelmed and permits for a smoother, extra manageable distribution of requests throughout the obtainable infrastructure.
Our journey in exploring AI mannequin scaling options has been an journey, which has led us to in the end create the scaling expertise on BentoCloud — a platform that encapsulates all our learnings.
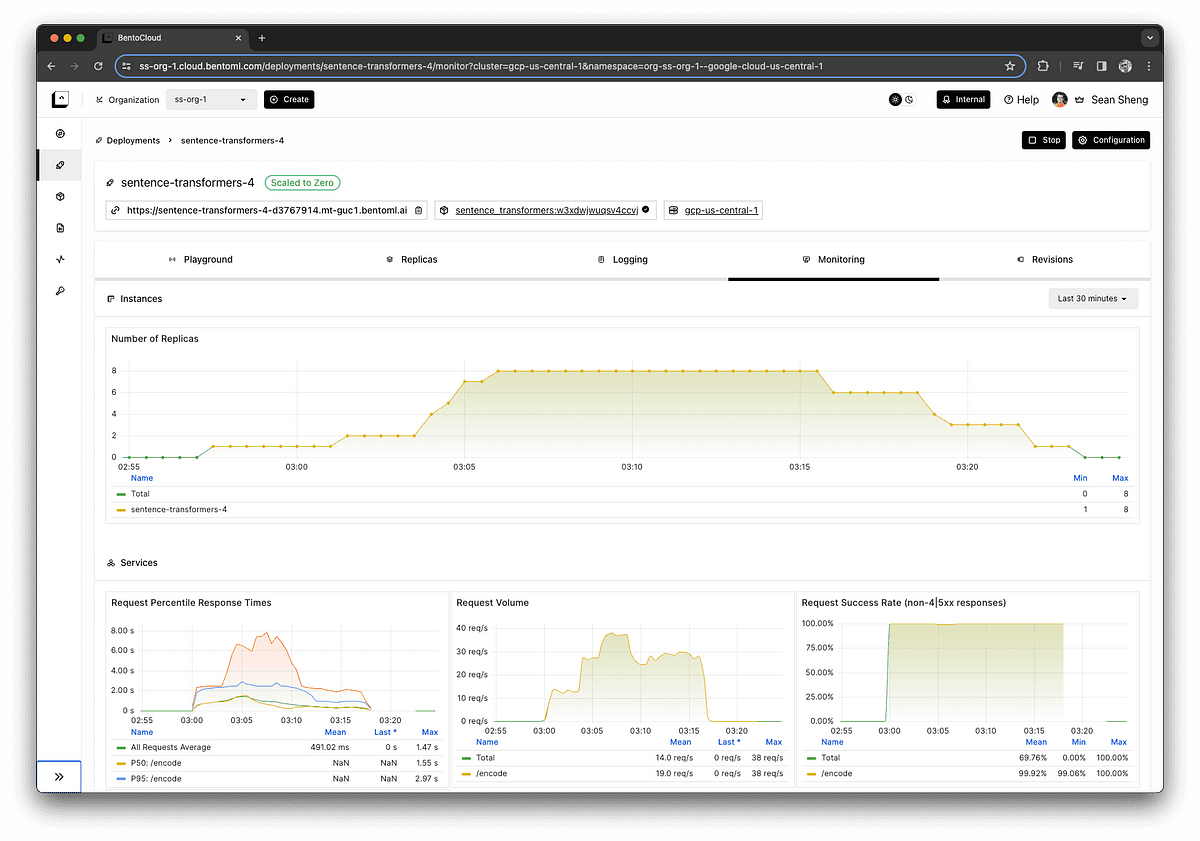
To keep away from the impression of a promotion, we’ll illustrate our level with an image that’s value a thousand phrases. The monitoring dashboard under demonstrates the correlation between incoming requests and the scaling up of server situations.
Equally essential to scaling up is the flexibility to scale down. Because the requests waned to zero, the deployment lowered the variety of energetic situations accordingly. This potential ensures that no pointless prices are incurred for unused assets, aligning expenditure with precise utilization.

We hope the takeaway is that scaling for mannequin deployments ought to be thought of an essential side of manufacturing functions. Not like scaling CPU workloads, scaling mannequin deployments on GPUs presents distinctive challenges, together with chilly begin occasions, configuring scaling metrics, and orchestrating requests. When evaluating deployment platforms, their options to those challenges ought to be completely assessed.
[ad_2]